分析
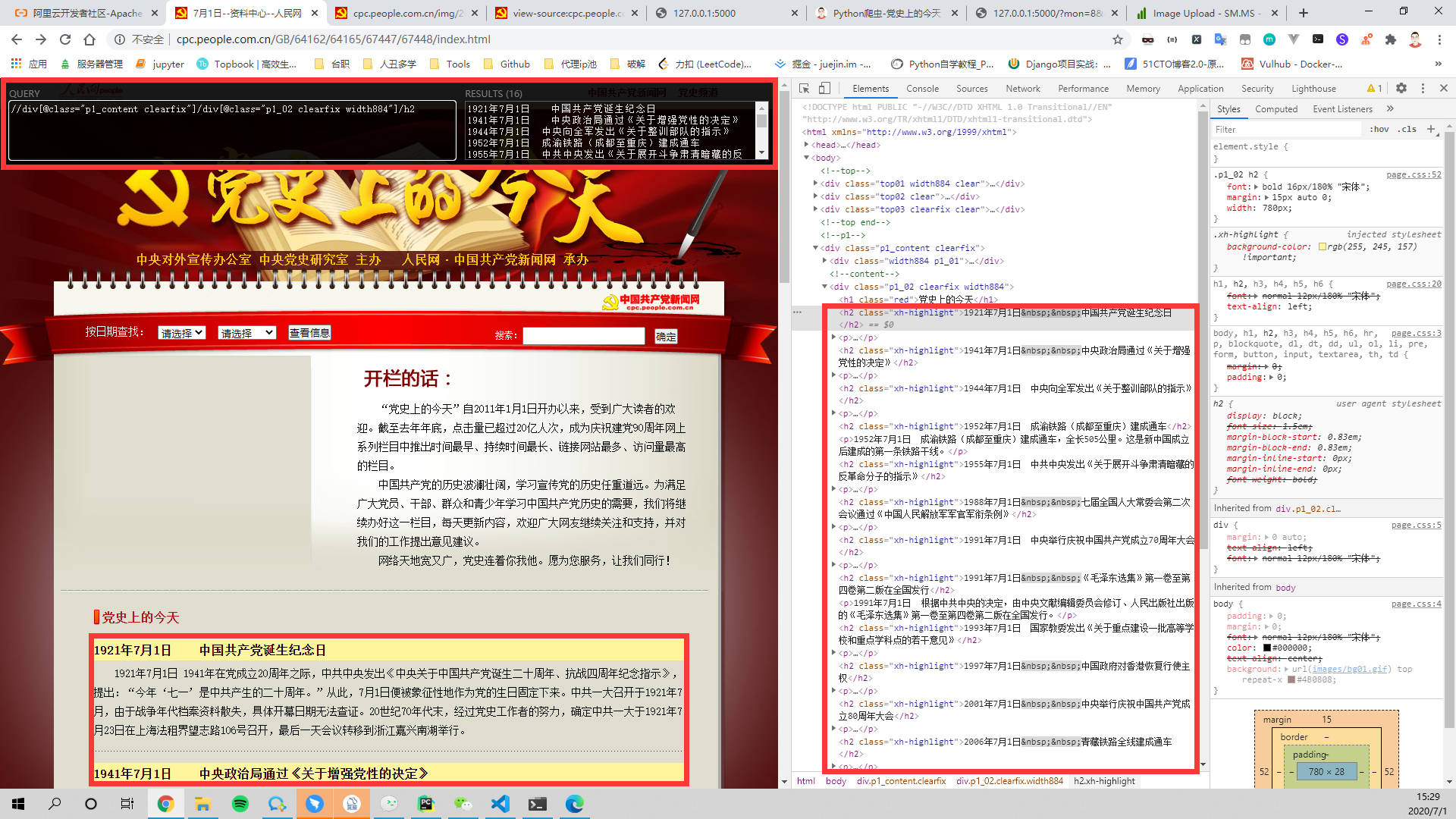
- 分析结构,可以发现标题都是h2标签,内容都是p标签,那就直接爬呗!!!
import requests
url = 'http://cpc.people.com.cn/GB/64162/64165/67447/67448/index.html'
response = requests.get(url)
print(response.text)
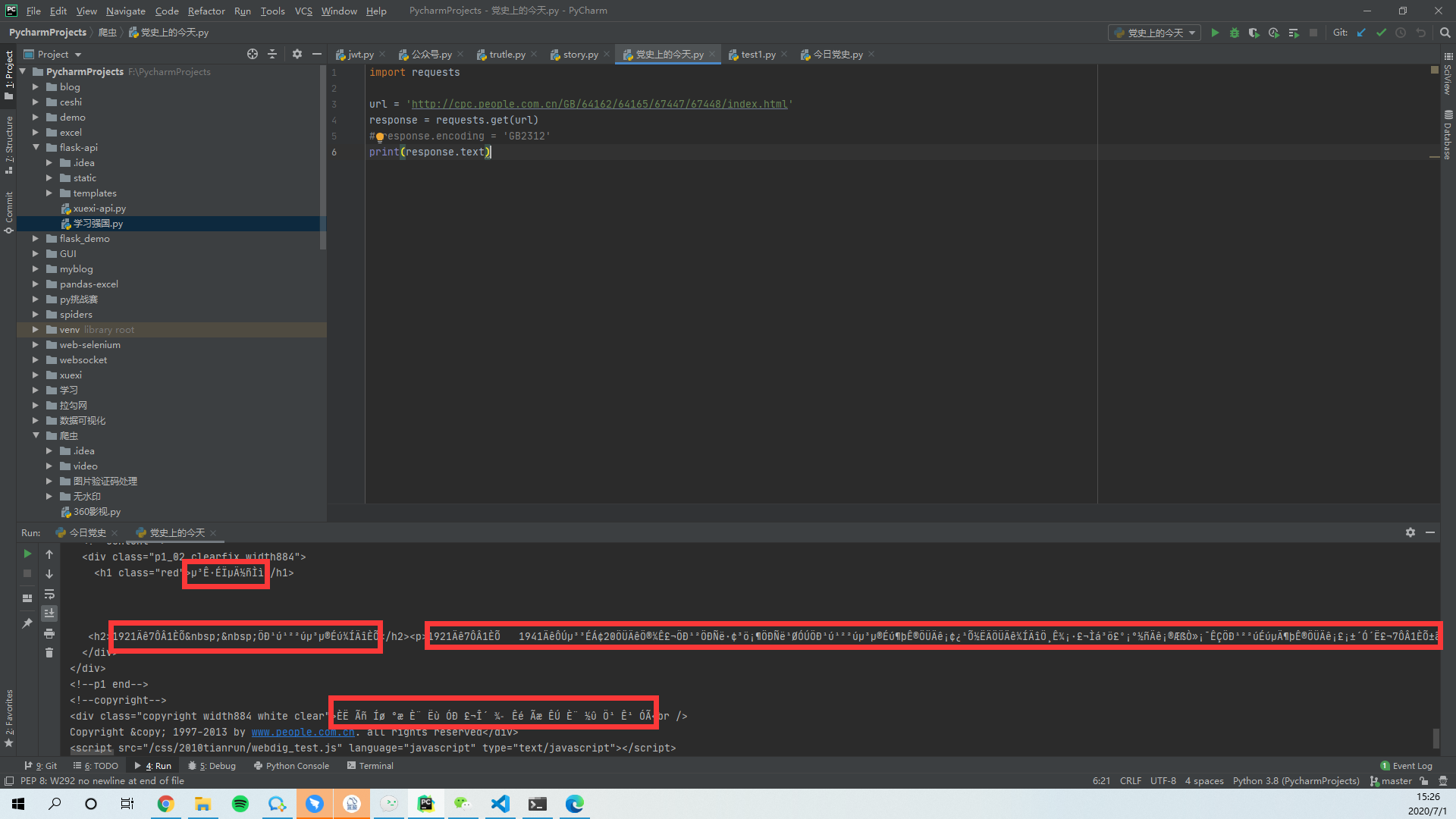
发现中文乱码
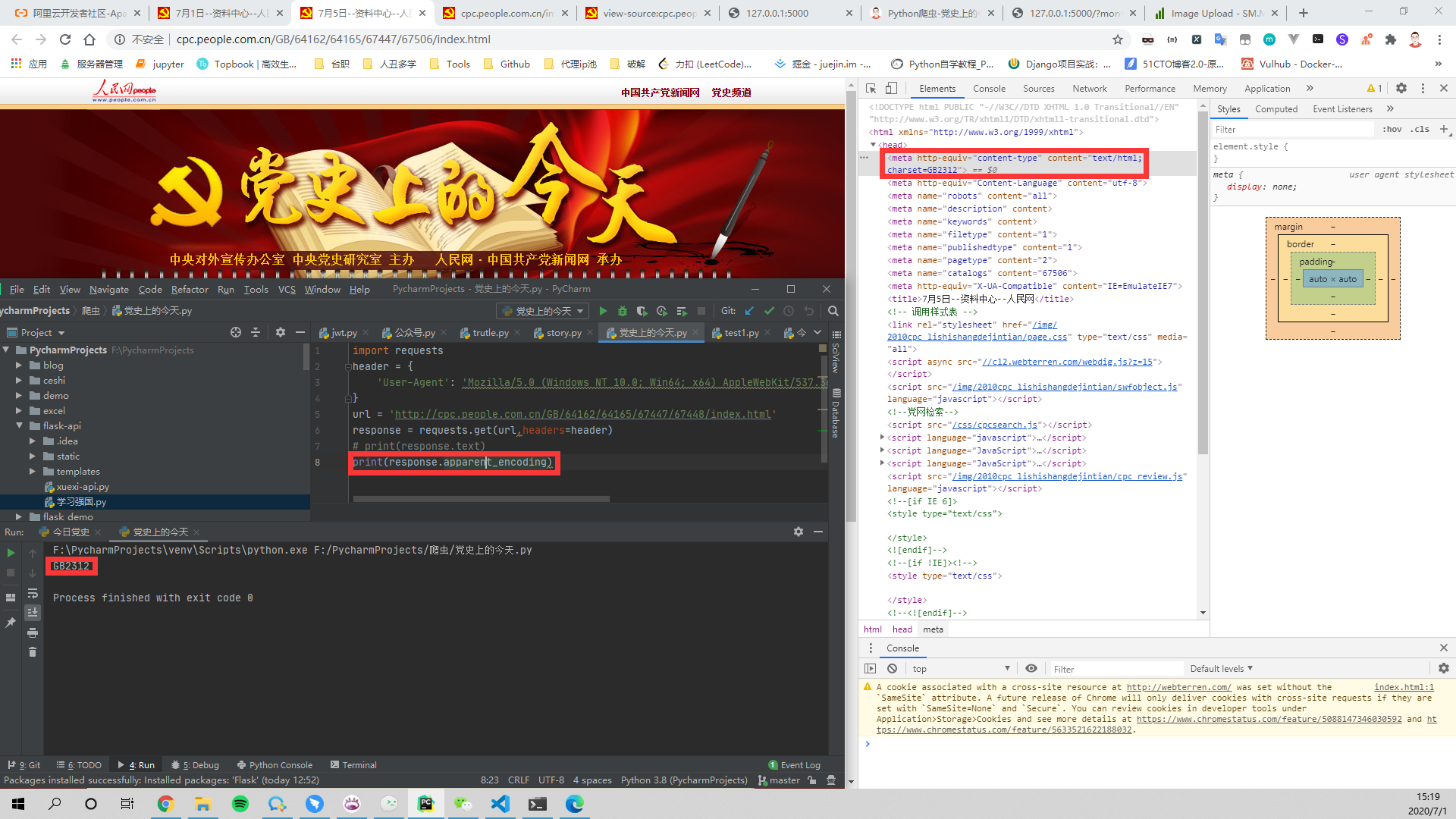
查看编码结果是GB2312,这就好办了,进行解码不就完事了
import requests
url = 'http://cpc.people.com.cn/GB/64162/64165/67447/67448/index.html'
response = requests.get(url)
response.encoding = 'GB2312'
print(response.text)
对比网页源代码发现内容一致,说明人民网没做任何反爬机制,这emmm
- 获取想要的内容
import requests
from lxml import etree
url = f'http://cpc.people.com.cn/GB/64162/64165/67447/67448/index.html'
response = requests.get(url)
response.encoding = 'GB2312'
# print(response.text)
html = etree.HTML(response.text)
title_pat = '//div[@class="p1_content clearfix"]/div[@class="p1_02 clearfix width884"]/h2/text()'
des_pat = '//div[@class="p1_content clearfix"]/div[@class="p1_02 clearfix width884"]/p/text()'
title = html.xpath(title_pat)
des = html.xpath(des_pat)
# 转换为元组
itemZip = zip(title, des)
# 转换为字典
content = dict(itemZip)
print(content)
- 我们不知想要当天的,我们还要其他的,分析网址
http://cpc.people.com.cn/GB/64162/64165/67447/67448/index.html
http://cpc.people.com.cn/GB/64162/64165/67447/67449/index.html
http://cpc.people.com.cn/GB/64162/64165/67447/67450/index.html
http://cpc.people.com.cn/GB/64162/64165/67447/67458/index.html
http://cpc.people.com.cn/GB/64162/64165/67447/67506/index.html
发现前面几个还是有规律的,后面就乱序了,这。。,我们从按钮入手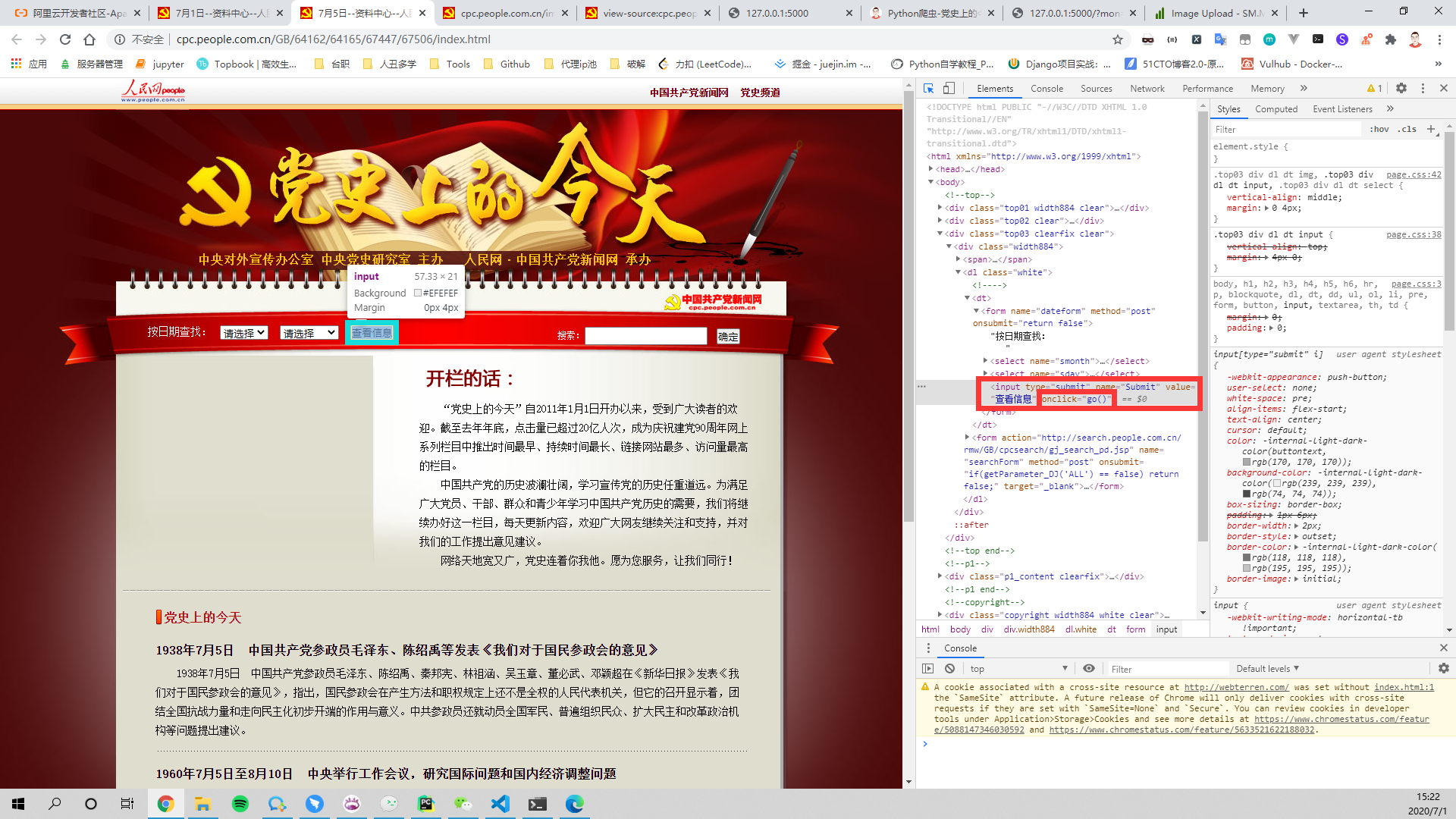
发现查看信息按钮是通过JavaScript脚本go()函数执行的,接下来就是寻找go函数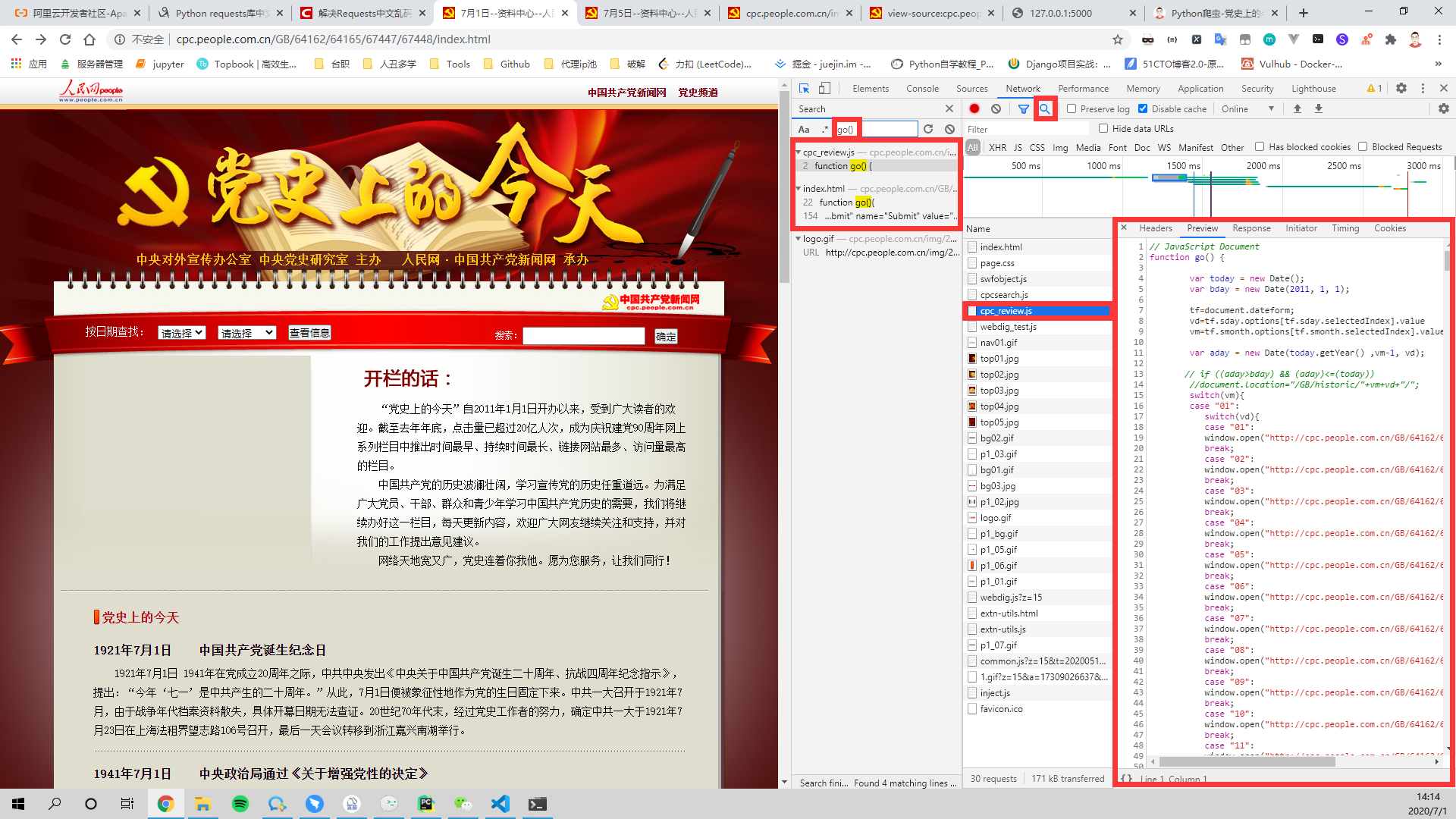
发现有2个位置有go()函数,点进去可以发现只有cpc_review.js才是我们想要的,找到JavaScript部分就好办了。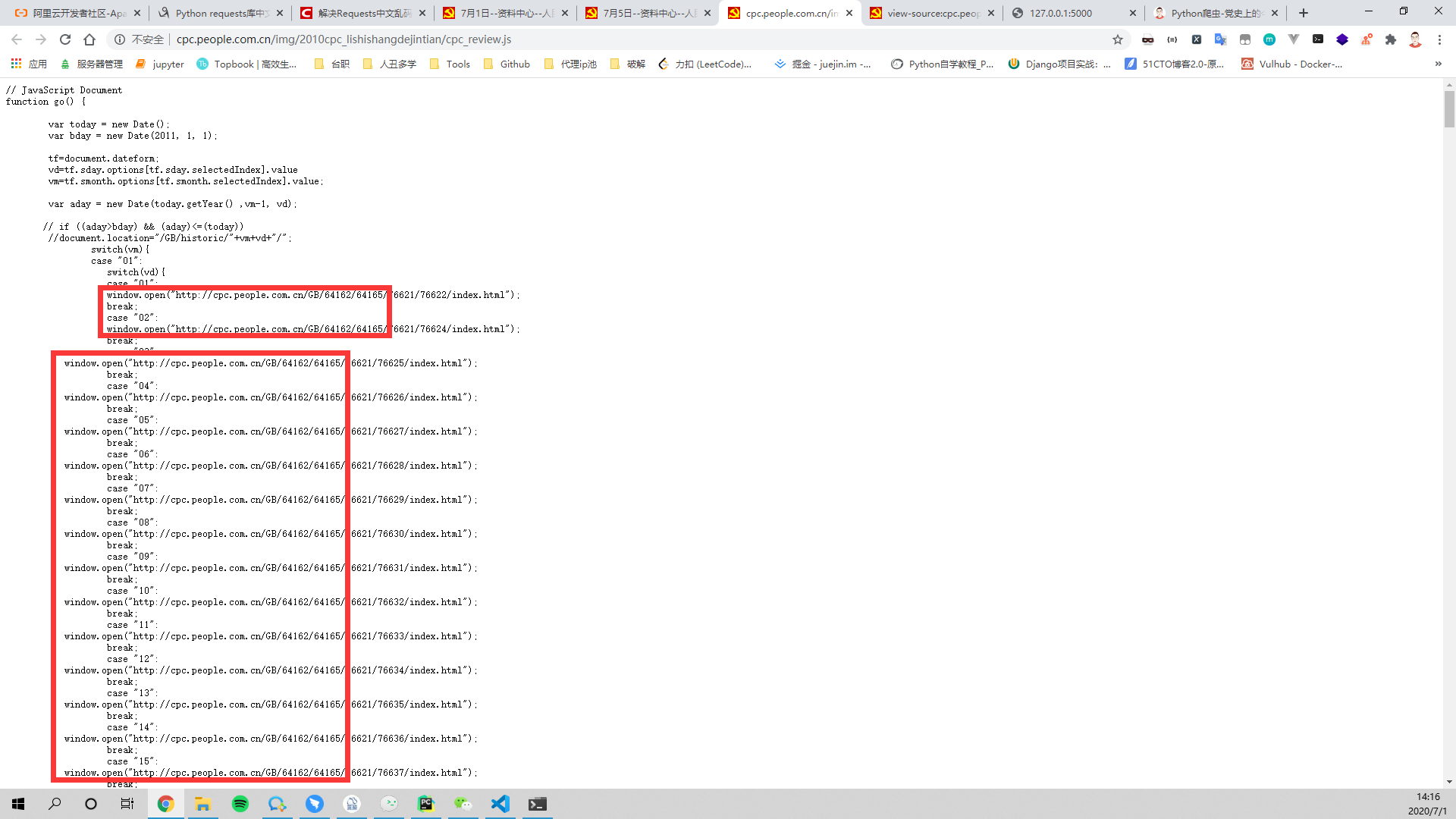
发现这不就是switch-case 语句,先通过第一个case分析月份再通过第二个case在定位到月份
显而易见链接前半部分都是相同的,后办部分为月/日,最终确认链接为http://cpc.people.com.cn/GB/64162/64165/月/日/index.html
这就好办了 那就直接爬呗
但月份正则并不好提取,反正就12个月份,直接手撸呗!!!
上代码hhhh
import re
import requests
monuth = [76621, 77552, 77585, 78561, 79703, 82273, 67447, 68640, 70293, 70486, 72301, 74856]
day_list = []
for item in monuth:
url = 'http://cpc.people.com.cn/img/2010cpc_lishishangdejintian/cpc_review.js'
response = requests.get(url).text
url_pat = f'http://cpc.people.com.cn/GB/64162/64165/{item}/(.*?)/index.html'
url = re.compile(url_pat).findall(response)
day_list.append(url)
print(day_list)
项目封装
# 导入包
import re
import requests
import time
from lxml import etree
monuth_list = [76621, 77552, 77585, 78561, 79703, 82273, 67447, 68640, 70293, 70486, 72301, 74856]
day_list = []
def day():
'''
:return:
'''
for item in monuth_list:
url = 'http://cpc.people.com.cn/img/2010cpc_lishishangdejintian/cpc_review.js'
response = requests.get(url).text
url_pat = f'http://cpc.people.com.cn/GB/64162/64165/{item}/(.*?)/index.html'
url = re.compile(url_pat).findall(response)
day_list.append(url)
# print(day_list)
def search(mon:int, day:int):
'''
搜索获取今日党史
:param mon: 月
:param day: 日
:return: 内容
'''
mon = monuth_list[mon - 1]
day = day_list[monuth_list.index(mon)][day - 1]
url = f'http://cpc.people.com.cn/GB/64162/64165/{mon}/{day}/index.html'
response = requests.get(url)
response.encoding = 'GB2312'
html = etree.HTML(response.text)
title_pat = '//div[@class="p1_content clearfix"]/div[@class="p1_02 clearfix width884"]/h2/text()'
des_pat = '//div[@class="p1_content clearfix"]/div[@class="p1_02 clearfix width884"]/p/text()'
title = html.xpath(title_pat)
des = html.xpath(des_pat)
itemZip = zip(title, des)
# print(dict(itemZip))
return dict(itemZip)
if __name__ == '__main__':
day()
monuth = time.localtime().tm_mon
day = time.localtime().tm_mday
print(search(monuth, day))
Flask分装api
# 导入包
import re
import requests
import time
from lxml import etree
from flask import Flask, request, json, Response
monuth_list = [76621, 77552, 77585, 78561, 79703, 82273, 67447, 68640, 70293, 70486, 72301, 74856]
day_list = []
def day():
'''
:return:
'''
for item in monuth_list:
url = 'http://cpc.people.com.cn/img/2010cpc_lishishangdejintian/cpc_review.js'
response = requests.get(url).text
url_pat = f'http://cpc.people.com.cn/GB/64162/64165/{item}/(.*?)/index.html'
url = re.compile(url_pat).findall(response)
day_list.append(url)
def search(mon, day):
'''
搜索获取今日党史
:param mon: 月
:param day: 日
:return: 内容
'''
mon = monuth_list[int(mon) - 1]
day = day_list[monuth_list.index(int(mon))][int(day) - 1]
url = f'http://cpc.people.com.cn/GB/64162/64165/{mon}/{day}/index.html'
response = requests.get(url)
response.encoding = 'GB2312'
html = etree.HTML(response.text)
title_pat = '//div[@class="p1_content clearfix"]/div[@class="p1_02 clearfix width884"]/h2/text()'
des_pat = '//div[@class="p1_content clearfix"]/div[@class="p1_02 clearfix width884"]/p/text()'
title = html.xpath(title_pat)
des = html.xpath(des_pat)
itemZip = zip(title, des)
# print(dict(itemZip))
return dict(itemZip)
app = Flask(__name__)
@app.route('/')
def index():
mon = request.args.get("mon")
day = request.args.get("day")
if mon == None or day == None:
mon = time.localtime().tm_mon
day = time.localtime().tm_mday
print(mon, day)
res = {
'code': 0,
'tips': '获取成功',
'data': search(mon, day)
}
return Response(json.dumps(res, ensure_ascii=False), mimetype='application/json')
if __name__ == '__main__':
day()
app.run()