线程进程协程关系与创建 –> 重要 –> 阿里面试时被问到
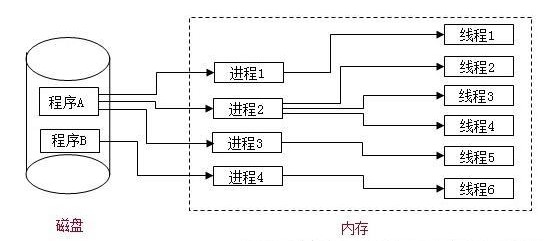
- 进程:一个运行的程序(代码)就是一个进程,没有运行的代码叫程序,进程是系统资源分配的最小单位,进程拥有自己独立的内存空间,所有进程间数据不共享,开销大。
- 线程: cpu调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程存在,一个进程至少有一个线程,叫主线程,而多个线程共享内存(数据共享,共享全局变量),从而极大地提高了程序的运行效率。
- 协程: 是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操中栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
- 协程和线程一样共享堆,不共享栈
- 协程和线程的区别是:协程避免了无意义的调度,由此可以提高性能;同时,协程也失去了标准线程使用多CPU的能力
_thread 多线程
# 导入包
import _thread
import time
# 为线程定义一个函数
def print_time(threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print("%s: %s" % (threadName, time.ctime(time.time())))
# 创建两个线程
try:
# 创建线程 thread.start_new_thread(function, args[, kwargs])
_thread.start_new_thread(print_time, ("Thread-1", 2,))
_thread.start_new_thread(print_time, ("Thread-2", 4,))
except:
print("Error: 无法启动线程")
# 主线程等待,否则直接退出
while 1:
pass
threading 多线程
# 导入包
import threading
import time
exitFlag = 0
# 继承父类threading.Thread
class myThread(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
# 把要执行的代码写到run函数里面 线程在创建后会直接运行run函数
def run(self):
print("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
print(exitFlag)
threadName.exit()
time.sleep(delay)
print("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("退出主线程")
threading 多线程同步
# 导入包
import threading
import time
class myThread(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print("退出主线程")
Queue线程优先级队列
- Queue.qsize () 返回队列的大小
- Queue.empty () 如果队列为空,返回 True, 反之 False
- Queue.full () 如果队列满了,返回 True, 反之 False
- Queue.full 与 maxsize 大小对应
- Queue.get ([block [, timeout]]) 获取队列,timeout 等待时间
- Queue.get_nowait () 相当 Queue.get (False)
- Queue.put (item) 写入队列,timeout 等待时间
- Queue.put_nowait (item) 相当 Queue.put (item, False)
- Queue.task_done () 在完成一项工作之后,Queue.task_done () 函数向任务已经完成的队列发送一个信号
- Queue.join () 实际上意味着等到队列为空,再执行别的操作
import queue
import threading
import time
exitFlag = 0
class myThread(threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print("开启线程:" + self.name)
process_data(self.name, self.q)
print("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 创建新线程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print("退出主线程")